1.Lokalne bazy danych - są to najprostsze bazy danych, które w całości znajdują się na jednym komputerze np. prosta baza zawierająca spis ludności w danym mieście. Baza ta będzie się zawierać tylko w jednej tabeli. Wszelkie zmiany użytkownik będzie bezpośrednio nanosił na ta tabele np. dodawanie, usuwanie lub aktualizację poszczególnych rekordów. Przykładem lokalnych baz danych mogą tu być: Access, Paradox, dBase.
2.Bazy typu klient-server - główna baza tego typu jest przechowywana w zasobach serwera, który to na ogół jest wydzielony jako osobny komputer. Dostęp do niego jest realizowany za pośrednictwem innych komputerów – oczywiście przez sieć, zatem nie musza się znajdować blisko siebie by korzystać z takiej bazy. Użytkownicy korzystając z takiej bazy nie korzystają bezpośrednio z jej zasobów, ponieważ odbywa się to za pośrednictwem programów zwanych klientami. Jeśli chodzi o serwery to najbardziej popularne na rynku obecnie są produkty firm: InterBase, Oracle, Sybase, Informix oraz Microsoft. Bardzo ważna cechą serwera jest możliwość korzystania wielu użytkowników, a wszystko to związane jest z licencją sprzedawaną przez producentów tego oprogramowania.

Ze względu na architekturę baz danych można wyróżnić:
1. Bazy jednowarstwowe, które wykonują natychmiast wszelkiego rodzaje zmiany, zaś program, który udostępnia użytkownikowi zawartość bazy ma z nim bezpośredni kontakt.
2. Bazy dwuwarstwowe, w których klient porozumiewa się z serwerem za pomocą specjalnych sterowników. Jeśli chodzi o samo połączenie to jest ono zależne od samego serwera, natomiast kontrolowanie poprawności danych zależy od klienta. Rozwiązanie takie wiąże się ze sporym obciążeniem programu klienckiego.
Obecnie ludzie, którzy zajmują się na co dzień bazami danych mogą łatwo stwierdzić, że różnią się one pomiędzy sobą w wielu aspektach. Praktycznie każda baza tworzy swoją własną kategorię i trudno je zaszufladkować. Jako cechy charakterystyczne dla danej grupy baz wyodrębnić można:
a. model danych (data model)
b. język zapytań (query language),
c. model obliczeniowy (computational model).
Bazy danych można podzielić według struktur danych, których używają:
1. Bazy proste (kartotekowe) - każda tablica danych jest samodzielnym dokumentem i nie może współpracować z innymi tablicami. Do baz tego typu należą liczne programy typu - książka telefoniczna, książka kucharska, spis książek, kaset lub płyt. Wspólną cechą tych baz jest ich zastosowanie w jednym wybranym celu. 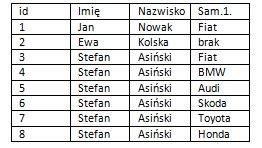
2. Relacyjne bazy danych (RDB) - wiele tablic danych może współpracować ze sobą. Bazy relacyjne posiadają wewnętrzne języki programowania (SQL), za pomocą których możemy tworzyć własne menu oraz zaawansowane funkcje obsługi danych. Relacyjne bazy danych (jak również przeznaczony dla nich standard (SQL) oparte są na kilku prostych zasadach:
a. Wszystkie wartości danych oparte są na prostych typach danych.
b. Wszystkie dane w bazie relacyjnej przedstawiane są w formie dwuwymiarowych tabel (w matematycznym żargonie noszących nazwę „relacji”). Każda tabela zawiera zero lub więcej wierszy (w tymże żargonie - „krotki”) i jedną lub więcej kolumn („atrybuty”). Na każdy wiersz składają się jednakowo ułożone kolumny wypełnione wartościami, które z kolei w każdym wierszu mogą być inne.
c. Po wprowadzeniu danych do bazy możliwe jest porównywanie wartości z różnych kolumn, zazwyczaj również z różnych tabel, i scalanie wierszy, gdy pochodzące z nich wartości są zgodne. Umożliwia to wiązanie danych i wykonywanie stosunkowo złożonych operacji w granicach całej bazy danych.
d. Wszystkie operacje wykonywane są w oparciu o logikę, bez względu na położenie wiersza tabeli. Wiersze w relacyjnej bazie danych przechowywane są w porządku zupełnie dowolnym - nie musi on odzwierciedlać ani kolejności ich wprowadzania, ani kolejności ich przechowywania.
e. Z braku możliwości identyfikacji wiersza przez jego pozycję pojawia się potrzeba obecności jednej lub więcej kolumn niepowtarzalnych w granicach całej tabeli, pozwalających odnaleźć konkretny wiersz. Kolumny te określa się jak „klucz podstawowy” (primary key) tabeli.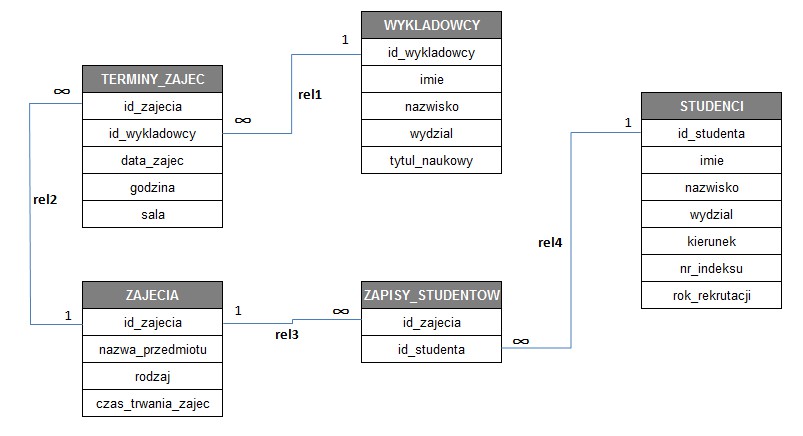
3. Obiektowe bazy danych (ODB) - nie są one zdefiniowane żadnym oficjalnym standardem. Obowiązujący obecnie standard opracowany przez ODMG został opublikowany w 1993 roku. Jednym z podstawowych celów modelu obiektowego jest bezpośrednie odwzorowanie obiektów i powiązań miedzy nimi wchodzących w skład aplikacji na zbiór obiektów i powiązań w bazie danych. Dzięki mechanizmom obiektowym można też zwiększyć niezależność danych od aplikacji poprzez przeniesienie procedur obsługi danych (w postaci metod) do systemu zarządzania bazą. Model danych w obiektowych bazach danych posługuje się pojęciami takimi jak klasy, atrybuty, metody, udostępnia identyfikatory obiektów (OID), hermetyzacje danych oraz metod i wielokrotnego dziedziczenia. Obiektowe bazy danych łączą własności obiektowości i obiektowych języków programowania z możliwościami systemów bazodanowych. Rozszerzają możliwości obiektowych języków programowania (takich jak C++, Java czy Smalltalk) czyniąc z nich narzędzia do łatwego i efektywneg
4. Strumieniowe bazy danych to bazy danych, w których dane są przedstawione w postaci zbioru strumieni danych. System zarządzania taką bazą nazywany jest strumieniowym systemem zarządzania danymi (Data Stream Management System). Większość strumieniowych baz danych w chwili obecnej znajduje się w fazach prototypowych i nie powstały dotychczas komercyjne rozwiązania. .